
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 디바이스 드라이버
- file descriptors
- 텐서플로우
- 인터럽트
- 딥러닝
- demultiplexing
- Interrupt
- 3분 딥러닝
- 펌웨어
- Class Activation Map
- 밑바닥부터 시작하는 딥러닝
- 모두를 위한 딥러닝
- function call
- TensorFlow
- Router
- GPIO
- Switch
- RDT
- Network layer
- Generalized forward
- Linux
- 신경망 첫걸음
- 스위치
- 모두를 위한 딥러닝]
- 운영체제
- Transport layer
- LED 제어
- 리눅스
- LED
- 신경망
Archives
- Today
- Total
건조젤리의 저장소
7-3. DQN 구현 (Nature 2015) 본문
김성훈 교수님의 강의내용을 정리한 내용입니다.
출처 : http://hunkim.github.io/ml/
모두를 위한 머신러닝/딥러닝 강의
hunkim.github.io

네트워크 분리 방법을 구현해보자.

DQN 2013에서는 학습할 데이터들을 배치 처리하는 과정을 추가하였다.

추가적으로 네트워크의 분리과정도 추가해보자.


Y를 계산할때 TargetDQN을 이용한다.
MainDQN / TargetDQN


두개의 네트워크를 만든 후, 메인 네트워크를 타겟 네트워크에 붙여 넣는다.
일정 간격마다 복사 과정을 수행하게 된다.
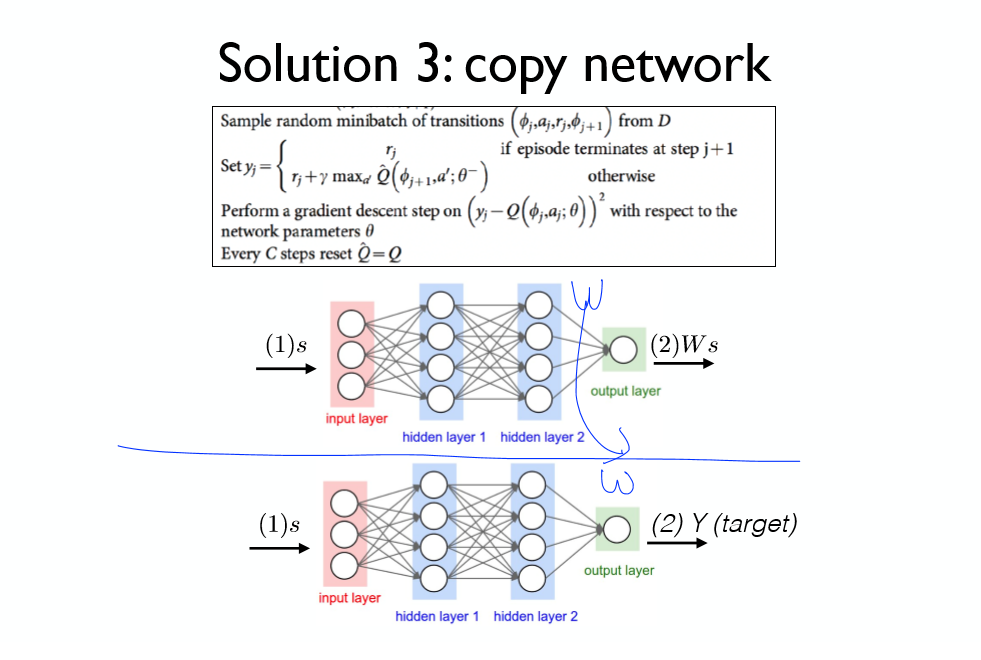
네트워크의 복사 = 가중치 값들의 복사

학습 가능한 변수들을 불러온 후,
.assign을 통해 Tensor값들을 할당하여 복사한다.
복사에 대한 operation들을 list에 저장해 return한다. (이를 session에서 실행하면 끝)
정리하자면
- 네트워크 2개를 만듬
- 메인 네트워크를 타겟 네트워크에 붙여넣기
- 환경 생성
- 액션을 사용하여 상태값들을 얻어옴
- 버퍼에 정보 저장
- 버퍼의 데이터를 이용, 타겟 네트워크를 사용해 Y값 설정
- 메인 네트워크 학습
- 메인 네트워크를 타겟 네트워크에 붙여넣기



타겟 네트워크와 메인 네트워크의 분리에 유의하자!




네트워크 분리를 적용한 방법의 성능이 월등하게 높은 것을 확인할 수 있다!
구현 코드 (환경: ubuntu:16.04 python 3.6)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
|
"""
Double DQN (Nature 2015)
http://web.stanford.edu/class/psych209/Readings/MnihEtAlHassibis15NatureControlDeepRL.pdf
Notes:
The difference is that now there are two DQNs (DQN & Target DQN)
y_i = r_i + 𝛾 * max(Q(next_state, action; 𝜃_target))
Loss: (y_i - Q(state, action; 𝜃))^2
Every C step, 𝜃_target <- 𝜃
"""
import numpy as np
import tensorflow as tf
import random
from collections import deque
import dqn
import gym
from typing import List
env = gym.make('CartPole-v0')
#env = gym.wrappers.Monitor(env, directory="gym-results/", force=True)
# Constants defining our neural network
INPUT_SIZE = env.observation_space.shape[0]
OUTPUT_SIZE = env.action_space.n
DISCOUNT_RATE = 0.99
REPLAY_MEMORY = 50000
BATCH_SIZE = 64
TARGET_UPDATE_FREQUENCY = 5
MAX_EPISODES = 5000
def replay_train(mainDQN: dqn.DQN, targetDQN: dqn.DQN, train_batch: list) -> float:
"""Trains `mainDQN` with target Q values given by `targetDQN`
Args:
mainDQN (dqn.DQN): Main DQN that will be trained
targetDQN (dqn.DQN): Target DQN that will predict Q_target
train_batch (list): Minibatch of replay memory
Each element is (s, a, r, s', done)
[(state, action, reward, next_state, done), ...]
Returns:
float: After updating `mainDQN`, it returns a `loss`
"""
states = np.vstack([x[0] for x in train_batch])
actions = np.array([x[1] for x in train_batch])
rewards = np.array([x[2] for x in train_batch])
next_states = np.vstack([x[3] for x in train_batch])
done = np.array([x[4] for x in train_batch])
X = states
Q_target = rewards + DISCOUNT_RATE * np.max(targetDQN.predict(next_states), axis=1) * ~done
y = mainDQN.predict(states)
y[np.arange(len(X)), actions] = Q_target
# Train our network using target and predicted Q values on each episode
return mainDQN.update(X, y)
def get_copy_var_ops(*, dest_scope_name: str, src_scope_name: str) -> List[tf.Operation]:
"""Creates TF operations that copy weights from `src_scope` to `dest_scope`
Args:
dest_scope_name (str): Destination weights (copy to)
src_scope_name (str): Source weight (copy from)
Returns:
List[tf.Operation]: Update operations are created and returned
"""
# Copy variables src_scope to dest_scope
op_holder = []
src_vars = tf.get_collection(
tf.GraphKeys.TRAINABLE_VARIABLES, scope=src_scope_name)
dest_vars = tf.get_collection(
tf.GraphKeys.TRAINABLE_VARIABLES, scope=dest_scope_name)
for src_var, dest_var in zip(src_vars, dest_vars):
op_holder.append(dest_var.assign(src_var.value()))
return op_holder
def bot_play(mainDQN: dqn.DQN, env: gym.Env) -> None:
"""Test runs with rendering and prints the total score
Args:
mainDQN (dqn.DQN): DQN agent to run a test
env (gym.Env): Gym Environment
"""
state = env.reset()
reward_sum = 0
while True:
env.render()
action = np.argmax(mainDQN.predict(state))
state, reward, done, _ = env.step(action)
reward_sum += reward
if done:
print("Total score: {}".format(reward_sum))
break
def main():
# store the previous observations in replay memory
replay_buffer = deque(maxlen=REPLAY_MEMORY)
last_100_game_reward = deque(maxlen=100)
with tf.Session() as sess:
mainDQN = dqn.DQN(sess, INPUT_SIZE, OUTPUT_SIZE, name="main")
targetDQN = dqn.DQN(sess, INPUT_SIZE, OUTPUT_SIZE, name="target")
sess.run(tf.global_variables_initializer())
# initial copy q_net -> target_net
copy_ops = get_copy_var_ops(dest_scope_name="target",
src_scope_name="main")
sess.run(copy_ops)
for episode in range(MAX_EPISODES):
e = 1. / ((episode / 10) + 1)
done = False
step_count = 0
state = env.reset()
while not done:
if np.random.rand() < e:
action = env.action_space.sample()
else:
# Choose an action by greedily from the Q-network
action = np.argmax(mainDQN.predict(state))
# Get new state and reward from environment
next_state, reward, done, _ = env.step(action)
if done: # Penalty
reward = -1
# Save the experience to our buffer
replay_buffer.append((state, action, reward, next_state, done))
if len(replay_buffer) > BATCH_SIZE:
minibatch = random.sample(replay_buffer, BATCH_SIZE)
loss, _ = replay_train(mainDQN, targetDQN, minibatch)
if step_count % TARGET_UPDATE_FREQUENCY == 0:
sess.run(copy_ops)
state = next_state
step_count += 1
print("Episode: {} steps: {}".format(episode, step_count))
# CartPole-v0 Game Clear Checking Logic
last_100_game_reward.append(step_count)
if len(last_100_game_reward) == last_100_game_reward.maxlen:
avg_reward = np.mean(last_100_game_reward)
if avg_reward > 199:
print(f"Game Cleared in {episode} episodes with avg reward {avg_reward}")
break
if __name__ == "__main__":
main()
|
cs |
'공부 기록 > 모두를 위한 딥러닝 (RL)' 카테고리의 다른 글
| 7-2. DQN 구현 (NIPS 2013) (1) | 2019.11.22 |
|---|---|
| 7-1. DQN (0) | 2019.11.22 |
| 6-3. Q-Network 구현 (Cart Pole) (0) | 2019.11.21 |
| 6-2. Q-Network 구현 (Frozen Lake) (0) | 2019.11.20 |
| 6-1. Q-Network (0) | 2019.11.19 |
'공부 기록/모두를 위한 딥러닝 (RL)' Related Articles
more




Comments