
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- TensorFlow
- LED 제어
- file descriptors
- Transport layer
- Class Activation Map
- 디바이스 드라이버
- 리눅스
- 펌웨어
- 스위치
- 딥러닝
- Linux
- Generalized forward
- 인터럽트
- RDT
- GPIO
- 텐서플로우
- 3분 딥러닝
- Interrupt
- 모두를 위한 딥러닝
- LED
- 밑바닥부터 시작하는 딥러닝
- 운영체제
- 신경망 첫걸음
- Router
- Network layer
- 신경망
- Switch
- function call
- 모두를 위한 딥러닝]
- demultiplexing
- Today
- Total
건조젤리의 저장소
6-1. Q-Network 본문
김성훈 교수님의 강의내용을 정리한 내용입니다.
출처 : http://hunkim.github.io/ml/
모두를 위한 머신러닝/딥러닝 강의
hunkim.github.io

이전 시간에는 테이블을 사용한 Q-learning 방법을 알아보았다.

하지만 실제 방대한 크기의 게임에 이를 적용하기 위해서는 테이블 크기가 기하 급수적으로 커지게 된다.

이를 해결하기 위해 테이블 보다 적은 크기를 가지는 노드들을 이용해 신경망을 만들고,
상태(s)와 행동(a)를 입력으로 주게 되면 보상값을 출력으로 받을 수 있는 구조를 이용해보자!

또한 상태(s)를 입력으로 넣게되면 취해야 할 행동들을 출력하는 형태의 신경망을 이용할 수도 있다.

정리하자면! 크게 2가지 형태로 나타낼 수 있다.
우리는 아래 형태의 신경망을 사용하게 될 것이다.

각 레이어들의 가중치를 통틀어 W라고 가정하면 출력은 Ws가 되고,
이 값이 최적의 Q값이 되도록 학습하면 된다.
Cost 함수는 위 그림을 참고하자.

y값 참고!
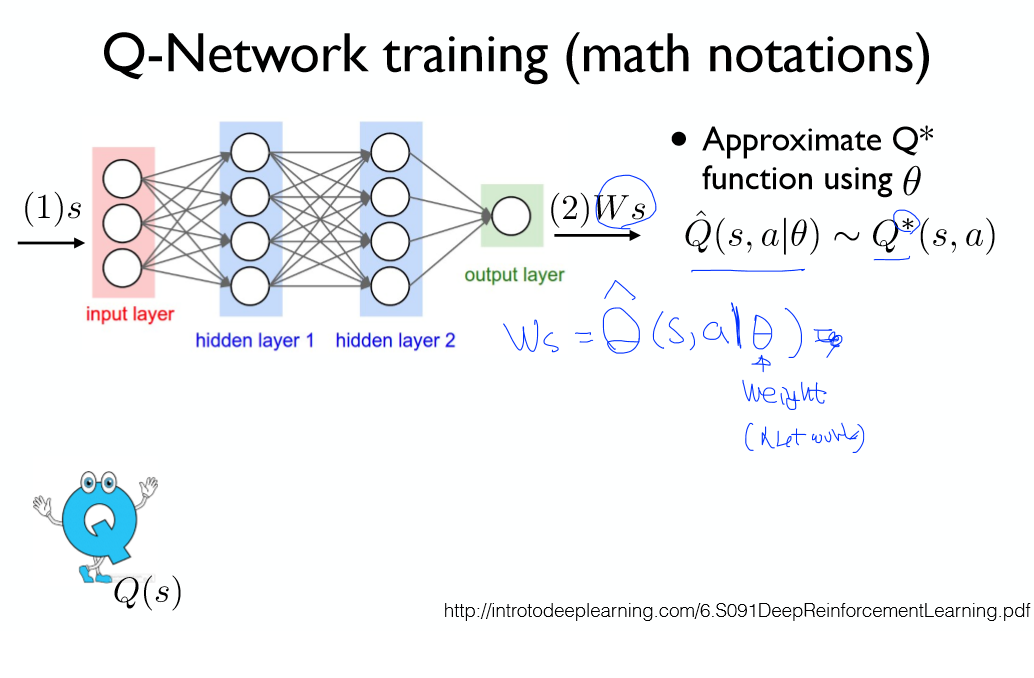
수학적인 표현으로 나타내면 위의 식과 같다.

Q의 예측값, 최적 Q값 차이의 제곱을 최소화하는 세타(가중치) 값을 구해야 한다.
이는 우리가 아는 선형회귀 방법과 동일!

- Q값 초기화
- 상태를 만듬 -> 처리 과정 만듬
- e-greedy, Q의 최대값중 하나를 선택
- 행동을 취하고 얻은 보상값으로 학습!
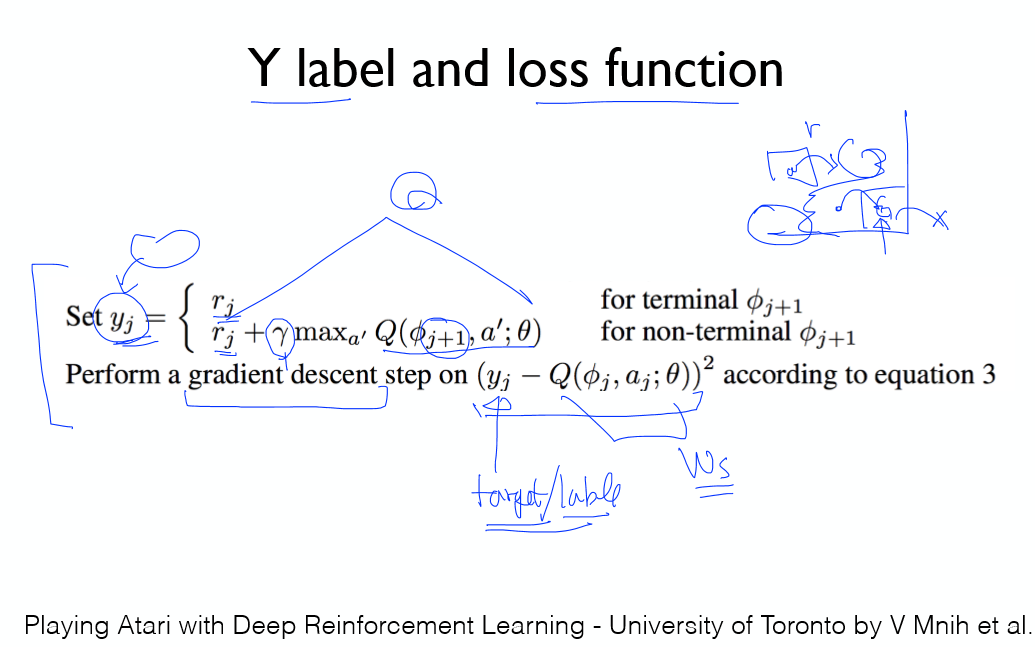
마지막 상태, 그 외의 상태일 경우 확인!
경사하강법을 적용!

이전에 공부했던 Windy Frozen Lake에서 아래의 식을 이용했으나,
신경망 구조를 가진 모델은 Cost함수를 통해 조금씩 학습하므로 아래식과 동일한 효과를 나타낸다.

위 식과 같은 Cost함수를 이용하게 되면 Q 근사값이 Q에 수렴할까?
아쉽게도 신경망에서는 수렴하지 않고 분산하게 된다.

발산이 일어나 학습이 되지 않는다.

이를 해결하는 DQN이 나오게 되었다!
'공부 기록 > 모두를 위한 딥러닝 (RL)' 카테고리의 다른 글
| 6-3. Q-Network 구현 (Cart Pole) (0) | 2019.11.21 |
|---|---|
| 6-2. Q-Network 구현 (Frozen Lake) (0) | 2019.11.20 |
| 5-2. Windy Frozen Lake 구현 (0) | 2019.11.19 |
| 5-1. Windy Frozen Lake (Non-deterministic world) (0) | 2019.11.19 |
| 4-2. Q-learning 구현 (table) (0) | 2019.11.19 |



