
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- LED
- function call
- Transport layer
- 3분 딥러닝
- Linux
- 딥러닝
- 모두를 위한 딥러닝
- demultiplexing
- Network layer
- 신경망
- file descriptors
- 디바이스 드라이버
- Switch
- 인터럽트
- LED 제어
- Class Activation Map
- 텐서플로우
- RDT
- Router
- Generalized forward
- TensorFlow
- Interrupt
- 모두를 위한 딥러닝]
- 밑바닥부터 시작하는 딥러닝
- 신경망 첫걸음
- GPIO
- 운영체제
- 펌웨어
- 스위치
- 리눅스
- Today
- Total
건조젤리의 저장소
7-2. DQN 구현 (NIPS 2013) 본문
김성훈 교수님의 강의내용을 정리한 내용입니다.
출처 : http://hunkim.github.io/ml/
모두를 위한 머신러닝/딥러닝 강의
hunkim.github.io


상태값을 받아온다.
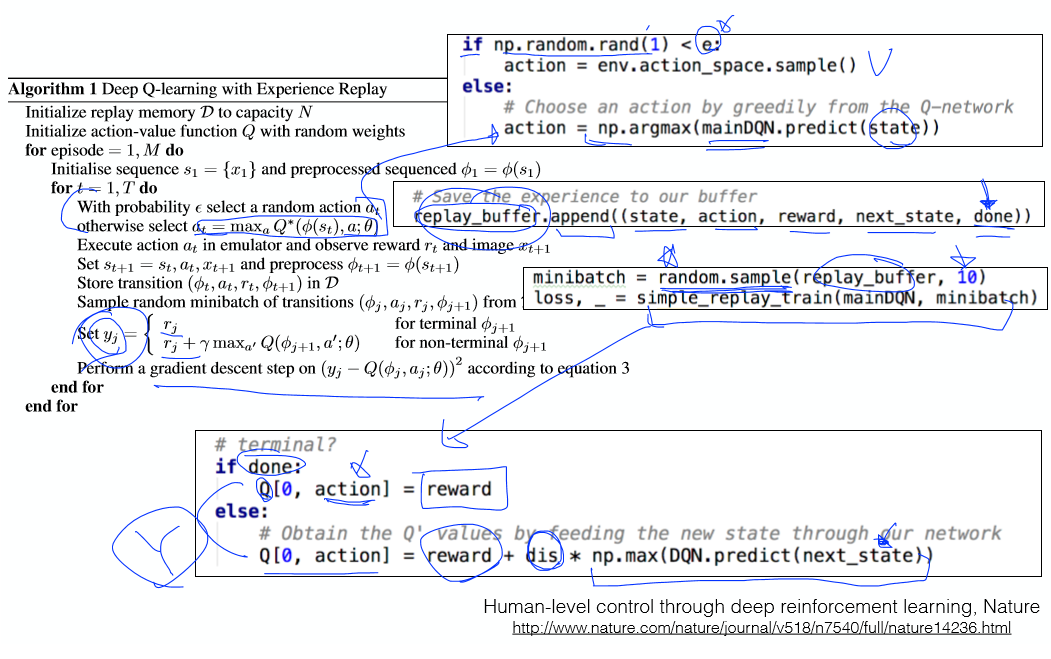
랜덤값 e를 이용해 e-greedy방법과 최대값 선택 방법중 하나를 실행한다.
상태값과 액션 등 여러 정보들을 버퍼에 넣는다.
배치에서 10개의 데이터를 랜덤으로 뽑아낸다.
학습을 위한 목표값 y를 얻어온 뒤, Cost함수를 이용해 네트워크를 학습시킨다.

위 2개 문제를 해결해보자.

네트워크 클래스를 선언한다.
이전의 얕은 네트워크를 더 깊게 수정하였다. (은닉층 10개)
분류문제가 아닌 회귀문제이므로 출력층의 활성화 함수는 사용하지 않는다.
예측과 학습을 위한 메소드도 추가로 만들어 주자.

버퍼를 만들기 위해 파이썬이 제공하는 큐를 사용하자.
.append를 이용해 값을 저장하고, 버퍼에 값이 과도하게 저장되는 것을 막기위해 일정 크기 이상이 되면 값을 빼낸다.
(제일 처음 값)
10번의 에피소드 마다 학습을 50번씩 시키게 된다. (버퍼에서 10개씩 뽑아서 학습)

배치 크기만큼 한번에 학습 시키기 위해, 스택을 이용해 값을 쌓는다.
현재 상태와 Q값을 쌓는다.
쌓은 값들을 이용하여 네트워크를 업데이트 한다.
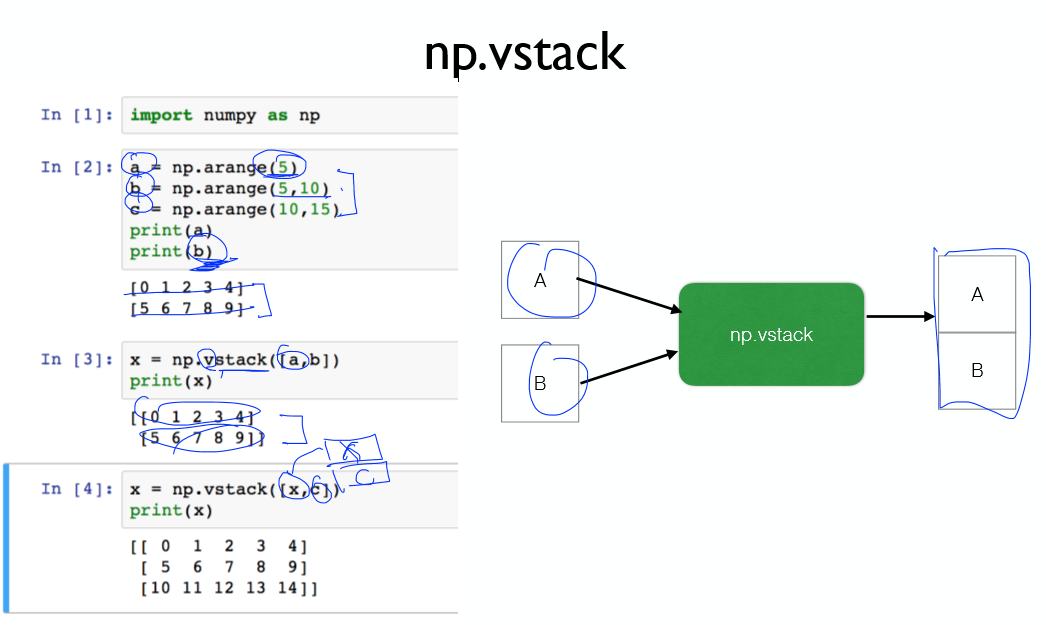
정리하자면
- 네트워크 빌드 및 실행
- 환경 빌드 및 액션 가져오기
- 액션에 대한 상태값 버퍼에 저장 (반복)
- 버퍼에서 샘플 추출 및 네트워크 학습 (반복)




네트워크를 이용해 테스트를 수행하는 코드이다.

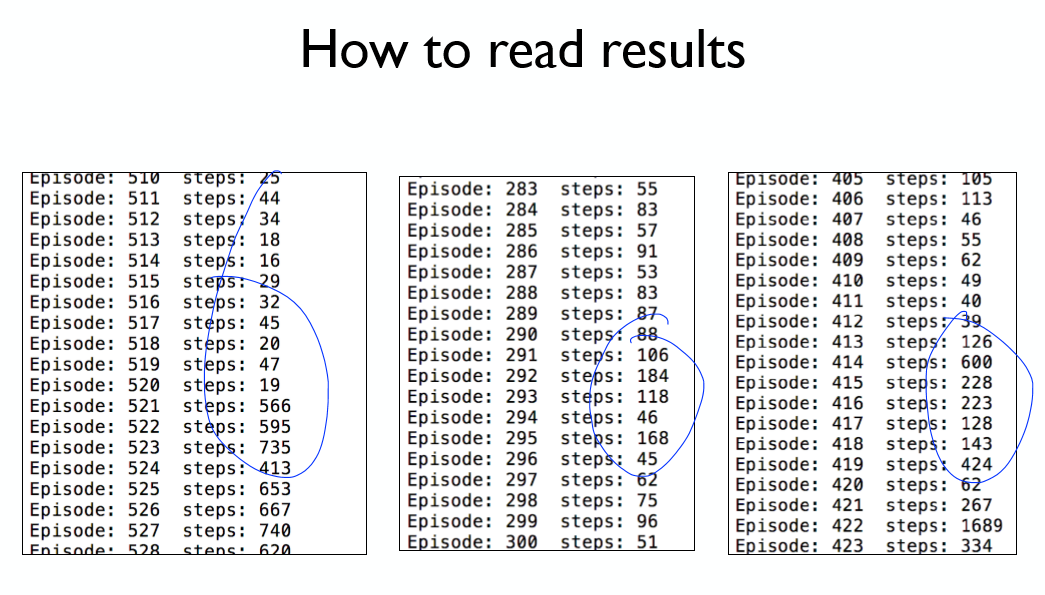
대부분의 결과에서 좋은 성능을 나타낸다. 하지만 일부분에서 불안정한 모습을 보인다!
다음 강의에서 이를 해결해보자!(네트워크 분리)
구현 코드 (환경: ubuntu:16.04 python 3.6)
DQN
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
import numpy as np
import tensorflow as tf
class DQN:
def __init__(self, session: tf.Session, input_size: int, output_size: int, name: str="main") -> None:
"""DQN Agent can
1) Build network
2) Predict Q_value given state
3) Train parameters
Args:
session (tf.Session): Tensorflow session
input_size (int): Input dimension
output_size (int): Number of discrete actions
name (str, optional): TF Graph will be built under this name scope
"""
self.session = session
self.input_size = input_size
self.output_size = output_size
self.net_name = name
self._build_network()
def _build_network(self, h_size=16, l_rate=0.001) -> None:
"""DQN Network architecture (simple MLP)
Args:
h_size (int, optional): Hidden layer dimension
l_rate (float, optional): Learning rate
"""
with tf.variable_scope(self.net_name):
self._X = tf.placeholder(tf.float32, [None, self.input_size], name="input_x")
net = self._X
net = tf.layers.dense(net, h_size, activation=tf.nn.relu)
net = tf.layers.dense(net, self.output_size)
self._Qpred = net
self._Y = tf.placeholder(tf.float32, shape=[None, self.output_size])
self._loss = tf.losses.mean_squared_error(self._Y, self._Qpred)
optimizer = tf.train.AdamOptimizer(learning_rate=l_rate)
self._train = optimizer.minimize(self._loss)
def predict(self, state: np.ndarray) -> np.ndarray:
"""Returns Q(s, a)
Args:
state (np.ndarray): State array, shape (n, input_dim)
Returns:
np.ndarray: Q value array, shape (n, output_dim)
"""
x = np.reshape(state, [-1, self.input_size])
return self.session.run(self._Qpred, feed_dict={self._X: x})
def update(self, x_stack: np.ndarray, y_stack: np.ndarray) -> list:
"""Performs updates on given X and y and returns a result
Args:
x_stack (np.ndarray): State array, shape (n, input_dim)
y_stack (np.ndarray): Target Q array, shape (n, output_dim)
Returns:
list: First element is loss, second element is a result from train step
"""
feed = {
self._X: x_stack,
self._Y: y_stack
}
return self.session.run([self._loss, self._train], feed)
|
cs |
main
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
|
"""
DQN (NIPS 2013)
Playing Atari with Deep Reinforcement Learning
https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
"""
import numpy as np
import tensorflow as tf
import random
import dqn
import gym
from collections import deque
env = gym.make('CartPole-v0')
#env = gym.wrappers.Monitor(env, 'gym-results/', force=True)
INPUT_SIZE = env.observation_space.shape[0]
OUTPUT_SIZE = env.action_space.n
DISCOUNT_RATE = 0.99
REPLAY_MEMORY = 50000
MAX_EPISODE = 5000
BATCH_SIZE = 64
# minimum epsilon for epsilon greedy
MIN_E = 0.0
# epsilon will be `MIN_E` at `EPSILON_DECAYING_EPISODE`
EPSILON_DECAYING_EPISODE = MAX_EPISODE * 0.01
def bot_play(mainDQN: dqn.DQN) -> None:
"""Runs a single episode with rendering and prints a reward
Args:
mainDQN (dqn.DQN): DQN Agent
"""
state = env.reset()
total_reward = 0
while True:
env.render()
action = np.argmax(mainDQN.predict(state))
state, reward, done, _ = env.step(action)
total_reward += reward
if done:
print("Total score: {}".format(total_reward))
break
def train_minibatch(DQN: dqn.DQN, train_batch: list) -> float:
"""Prepare X_batch, y_batch and train them
Recall our loss function is
target = reward + discount * max Q(s',a)
or reward if done early
Loss function: [target - Q(s, a)]^2
Hence,
X_batch is a state list
y_batch is reward + discount * max Q
or reward if terminated early
Args:
DQN (dqn.DQN): DQN Agent to train & run
train_batch (list): Minibatch of Replay memory
Eeach element is a tuple of (s, a, r, s', done)
Returns:
loss: Returns a loss
"""
state_array = np.vstack([x[0] for x in train_batch])
action_array = np.array([x[1] for x in train_batch])
reward_array = np.array([x[2] for x in train_batch])
next_state_array = np.vstack([x[3] for x in train_batch])
done_array = np.array([x[4] for x in train_batch])
X_batch = state_array
y_batch = DQN.predict(state_array)
Q_target = reward_array + DISCOUNT_RATE * np.max(DQN.predict(next_state_array), axis=1) * ~done_array
y_batch[np.arange(len(X_batch)), action_array] = Q_target
# Train our network using target and predicted Q values on each episode
loss, _ = DQN.update(X_batch, y_batch)
return loss
def annealing_epsilon(episode: int, min_e: float, max_e: float, target_episode: int) -> float:
"""Return an linearly annealed epsilon
Epsilon will decrease over time until it reaches `target_episode`
(epsilon)
|
max_e ---|\
| \
| \
| \
min_e ---|____\_______________(episode)
|
target_episode
slope = (min_e - max_e) / (target_episode)
intercept = max_e
e = slope * episode + intercept
Args:
episode (int): Current episode
min_e (float): Minimum epsilon
max_e (float): Maximum epsilon
target_episode (int): epsilon becomes the `min_e` at `target_episode`
Returns:
float: epsilon between `min_e` and `max_e`
"""
slope = (min_e - max_e) / (target_episode)
intercept = max_e
return max(min_e, slope * episode + intercept)
def main():
# store the previous observations in replay memory
replay_buffer = deque(maxlen=REPLAY_MEMORY)
last_100_game_reward = deque(maxlen=100)
with tf.Session() as sess:
mainDQN = dqn.DQN(sess, INPUT_SIZE, OUTPUT_SIZE)
init = tf.global_variables_initializer()
sess.run(init)
for episode in range(MAX_EPISODE):
e = annealing_epsilon(episode, MIN_E, 1.0, EPSILON_DECAYING_EPISODE)
done = False
state = env.reset()
step_count = 0
while not done:
if np.random.rand() < e:
action = env.action_space.sample()
else:
action = np.argmax(mainDQN.predict(state))
next_state, reward, done, _ = env.step(action)
if done:
reward = -1
replay_buffer.append((state, action, reward, next_state, done))
state = next_state
step_count += 1
if len(replay_buffer) > BATCH_SIZE:
minibatch = random.sample(replay_buffer, BATCH_SIZE)
train_minibatch(mainDQN, minibatch)
print("[Episode {:>5}] steps: {:>5} e: {:>5.2f}".format(episode, step_count, e))
# CartPole-v0 Game Clear Logic
last_100_game_reward.append(step_count)
if len(last_100_game_reward) == last_100_game_reward.maxlen:
avg_reward = np.mean(last_100_game_reward)
if avg_reward > 199.0:
print("Game Cleared within {} episodes with avg reward {}".format(episode, avg_reward))
break
if __name__ == "__main__":
main()
|
cs |
'공부 기록 > 모두를 위한 딥러닝 (RL)' 카테고리의 다른 글
| 7-3. DQN 구현 (Nature 2015) (0) | 2019.11.22 |
|---|---|
| 7-1. DQN (0) | 2019.11.22 |
| 6-3. Q-Network 구현 (Cart Pole) (0) | 2019.11.21 |
| 6-2. Q-Network 구현 (Frozen Lake) (0) | 2019.11.20 |
| 6-1. Q-Network (0) | 2019.11.19 |



