
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Generalized forward
- LED 제어
- Linux
- Transport layer
- Network layer
- file descriptors
- 디바이스 드라이버
- Interrupt
- 딥러닝
- 신경망 첫걸음
- Class Activation Map
- LED
- 펌웨어
- TensorFlow
- function call
- 모두를 위한 딥러닝
- 인터럽트
- 모두를 위한 딥러닝]
- 리눅스
- 3분 딥러닝
- 신경망
- demultiplexing
- 밑바닥부터 시작하는 딥러닝
- 운영체제
- Switch
- RDT
- GPIO
- 스위치
- 텐서플로우
- Router
- Today
- Total
건조젤리의 저장소
12-3. Tensorflow를 이용한 RNN 예제 실습 본문
김성훈 교수님의 강의내용을 정리한 내용입니다.
출처 : http://hunkim.github.io/ml/
모두를 위한 머신러닝/딥러닝 강의
hunkim.github.io
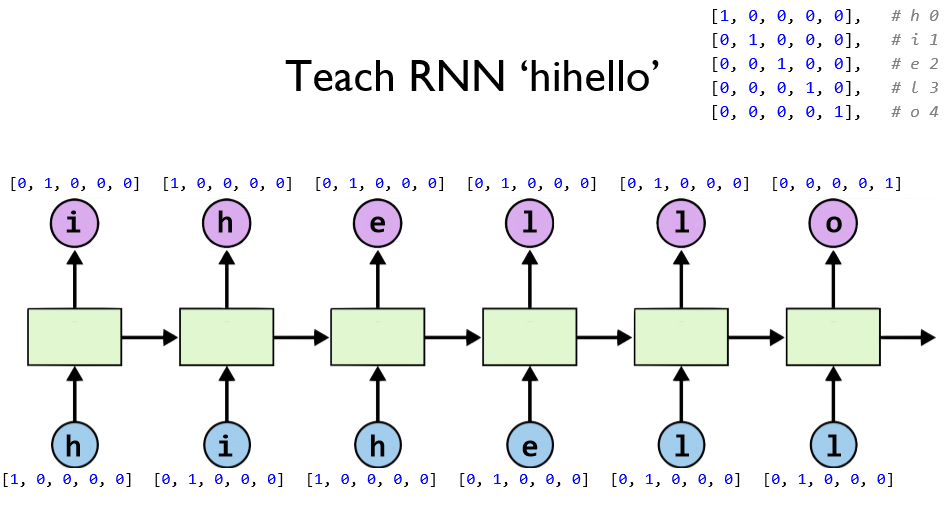
위와 같은 language 모델을 구현해보자.

RNN cell을 생성할때 원하는 종류를 선택할 수 있다.

cell을 생성하였으면 cell을 동작시키는 코드가 필요하다.

총 5개의 문자로 이루어진 단어이므로 hidden size는 5로 설정한다.
마찬가지로 input_dim또한 5로 설정한다.
하나의 단어만 학습할 것 이기 때문에 batch 크기는 1로 설정한다.
단어에서 마지막 부분은 들어갈 필요가 없으므로 6으로 설정한다.

one_hot 형식으로 데이터를 만든다.
* x_data는 여기서 아직 쓰이지 않음 (다음장 참고)

cell을 생성하고 실행한다.
initial_state에는 배치 크기를 넣어주면 된다.

RNN에서 cost값을 계산하는 방법은 위와같은 코드를 사용하면 된다. (sequence_loss)
이때 weights의 의미는 각각의 자리의 중요도라고 한다. (모두 1로 설정)
y값과 출력값이 유사한 값을 나타낼 수록 cost가 줄어든다.


학습을 위한 코드이다.

결과값을 확인하면 모델의 예측이 정확한 것을 볼 수 있다.
코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
# Lab 12 RNN
import tensorflow as tf
import numpy as np
tf.set_random_seed(777) # reproducibility
idx2char = ['h', 'i', 'e', 'l', 'o']
# Teach hello: hihell -> ihello
x_data = [[0, 1, 0, 2, 3, 3]] # hihell
x_one_hot = [[[1, 0, 0, 0, 0], # h 0
[0, 1, 0, 0, 0], # i 1
[1, 0, 0, 0, 0], # h 0
[0, 0, 1, 0, 0], # e 2
[0, 0, 0, 1, 0], # l 3
[0, 0, 0, 1, 0]]] # l 3
y_data = [[1, 0, 2, 3, 3, 4]] # ihello
num_classes = 5
input_dim = 5 # one-hot size
hidden_size = 5 # output from the LSTM. 5 to directly predict one-hot
batch_size = 1 # one sentence
sequence_length = 6 # |ihello| == 6
learning_rate = 0.1
X = tf.placeholder(
tf.float32, [None, sequence_length, input_dim]) # X one-hot
Y = tf.placeholder(tf.int32, [None, sequence_length]) # Y label
cell = tf.nn.rnn_cell.LSTMCell(name='basic_lstm_cell', num_units=hidden_size, state_is_tuple=True)
initial_state = cell.zero_state(batch_size, tf.float32)
outputs, _states = tf.nn.dynamic_rnn(
cell, X, initial_state=initial_state, dtype=tf.float32)
# FC layer
X_for_fc = tf.reshape(outputs, [-1, hidden_size])
# fc_w = tf.get_variable("fc_w", [hidden_size, num_classes])
# fc_b = tf.get_variable("fc_b", [num_classes])
# outputs = tf.matmul(X_for_fc, fc_w) + fc_b
outputs = tf.contrib.layers.fully_connected(
inputs=X_for_fc, num_outputs=num_classes, activation_fn=None)
# reshape out for sequence_loss
outputs = tf.reshape(outputs, [batch_size, sequence_length, num_classes])
weights = tf.ones([batch_size, sequence_length])
sequence_loss = tf.contrib.seq2seq.sequence_loss(
logits=outputs, targets=Y, weights=weights)
loss = tf.reduce_mean(sequence_loss)
train = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
prediction = tf.argmax(outputs, axis=2)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(50):
l, _ = sess.run([loss, train], feed_dict={X: x_one_hot, Y: y_data})
result = sess.run(prediction, feed_dict={X: x_one_hot})
print(i, "loss:", l, "prediction: ", result, "true Y: ", y_data)
# print char using dic
result_str = [idx2char[c] for c in np.squeeze(result)]
print("\tPrediction str: ", ''.join(result_str))
|
cs |
RNN에 문장 데이터를 넣을때 one-hot 인코딩 과정을 일일이 하기는 어렵다.
다음의 코드로 이 과정을 간단하게 수행할 수 있다.


하이퍼 파라미터 또한 이 코드를 사용하여 자동으로 설정할 수 있다.

학습 데이터와 Cost 함수를 정의한 후 학습을 수행하자.

출력 결과가 잘 나오게 된다.
코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
# Lab 12 Character Sequence RNN
import tensorflow as tf
import numpy as np
tf.set_random_seed(777) # reproducibility
sample = " if you want you"
idx2char = list(set(sample)) # index -> char
char2idx = {c: i for i, c in enumerate(idx2char)} # char -> index
# hyper parameters
dic_size = len(char2idx) # RNN input size (one hot size)
hidden_size = len(char2idx) # RNN output size
num_classes = len(char2idx) # final output size (RNN or softmax, etc.)
batch_size = 1 # one sample data, one batch
sequence_length = len(sample) - 1 # number of lstm rollings (unit #)
learning_rate = 0.1
sample_idx = [char2idx[c] for c in sample] # char to index
x_data = [sample_idx[:-1]] # X data sample (0 ~ n-1) hello: hell
y_data = [sample_idx[1:]] # Y label sample (1 ~ n) hello: ello
X = tf.placeholder(tf.int32, [None, sequence_length]) # X data
Y = tf.placeholder(tf.int32, [None, sequence_length]) # Y label
x_one_hot = tf.one_hot(X, num_classes) # one hot: 1 -> 0 1 0 0 0 0 0 0 0 0
cell = tf.nn.rnn_cell.LSTMCell(name='basic_lstm_cell',
num_units=hidden_size, state_is_tuple=True)
initial_state = cell.zero_state(batch_size, tf.float32)
outputs, _states = tf.nn.dynamic_rnn(
cell, x_one_hot, initial_state=initial_state, dtype=tf.float32)
# FC layer
X_for_fc = tf.reshape(outputs, [-1, hidden_size])
outputs = tf.contrib.layers.fully_connected(X_for_fc, num_classes, activation_fn=None)
# reshape out for sequence_loss
outputs = tf.reshape(outputs, [batch_size, sequence_length, num_classes])
weights = tf.ones([batch_size, sequence_length])
sequence_loss = tf.contrib.seq2seq.sequence_loss(
logits=outputs, targets=Y, weights=weights)
loss = tf.reduce_mean(sequence_loss)
train = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
prediction = tf.argmax(outputs, axis=2)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(50):
l, _ = sess.run([loss, train], feed_dict={X: x_data, Y: y_data})
result = sess.run(prediction, feed_dict={X: x_data})
# print char using dic
result_str = [idx2char[c] for c in np.squeeze(result)]
print(i, "loss:", l, "Prediction:", ''.join(result_str))
|
cs |
만약 굉장히 긴 문장을 학습 데이터로 주게되면 어떻게 될까?

학습 데이터를 일정 단위로 나누어 학습시키고자 한다.

위와 같은 코드를 사용하여 긴 학습 데이터를 일정 단위로 나눌 수 있다.

파라미터 값 설정은 위 그림과 같다.

이러한 구조로 데이터를 넣어 학습시키면 결과는 어떻게 될까?
미리 말하자면 잘 동작하지 않는다!
다음 장에서 이에 대한 설명이 나오게 된다.
'공부 기록 > 모두를 위한 딥러닝 (Basic)' 카테고리의 다른 글
| 12-5. Dynamic RNN (0) | 2019.11.14 |
|---|---|
| 12-4. Tensorflow를 이용한 RNN + Softmax layer 구현 (0) | 2019.11.13 |
| 12-2. Tensorflow를 이용한 RNN 기초 실습 (0) | 2019.11.13 |
| 12-1. RNN (0) | 2019.11.13 |
| 11-4. Tensorflow를 이용한 CNN의 구현 (0) | 2019.11.12 |



