
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- Router
- 스위치
- LED 제어
- Interrupt
- 모두를 위한 딥러닝]
- 펌웨어
- 딥러닝
- 운영체제
- file descriptors
- demultiplexing
- LED
- 인터럽트
- Transport layer
- 모두를 위한 딥러닝
- 신경망 첫걸음
- 텐서플로우
- Switch
- 리눅스
- RDT
- GPIO
- 밑바닥부터 시작하는 딥러닝
- function call
- Linux
- Class Activation Map
- 신경망
- TensorFlow
- 3분 딥러닝
- 디바이스 드라이버
- Generalized forward
- Network layer
- Today
- Total
건조젤리의 저장소
10-2. Initialize weights in a smart way 본문
김성훈 교수님의 강의내용을 정리한 내용입니다.
출처 : http://hunkim.github.io/ml/
모두를 위한 머신러닝/딥러닝 강의
hunkim.github.io
지난 시간에는 Vanishing gradient문제를 해결할 수 있는 방법으로 새로운 활성화 함수, ReLU를 알아보았습니다.
또다른 방법은 무엇이 있을까요?

모델의 가중치를 초기화 할 때 설정하는 값에 따라 결과는 아래 그림과 같이 달라질 수 있습니다.

같은 ReLU함수를 사용했음에도 초기값을 어떻게 설정하는지에 따라 결과가 달라진다.

만약 초기값을 0으로 주게되면 역전파시 미분값이 0이되므로 학습이 이루어 지지 않습니다.

이러한 결과를 막기 위해 어떠한 방법을 써야 할까요?
방법중 하나인 RBM이라는 방법이 있습니다.
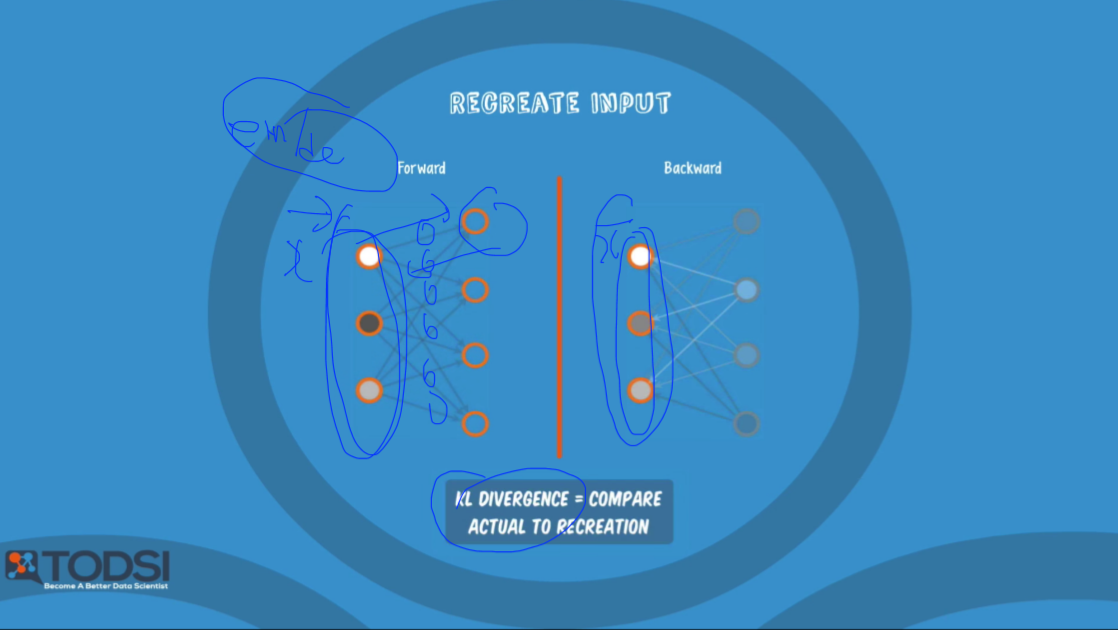
간단하게 설명하자면 서로 연결된 2개의 레이어에서
입력값을 Forward하여 output을 만들어 낸 후 Output을 Backward하여 나온 값과 입력값을 비교하여,
차이가 최소가 되도록 가중치값을 조정합니다.
이는 인코더/디코더의 형태와 비슷합니다.
이러한 과정을 모든 레이어 계층에 적용하여 모든 가중치의 적절한 값을 찾습니다.
이런 것을 Deep Belief Network(DBN)라고 부르기도 합니다.

이 과정이 끝나면 실제 데이터와 레이블을 가지고 학습을 시키면 된다.
이러한 가중치 초기화 과정을 거치게 되면 학습 시간이 더욱 단축된다고 합니다.
추가적인 설명을 원하면 다음의 블로그 링크를 참고하세요: https://www.whydsp.org/283
내맘대로 이해하는 Deep Belief Network와 Restricted Boltzmann Machine
김승일 모두의연구소 연구소장 모두의연구소 DeepLAB 랩짱 Deep Belief Network(DBN)과 Restriced Boltzmann Machine(RBM) 논문을 보면, Graph Theory로 중무장한 어려운 글들을 볼 수 있습니다. DBN을 좀 쉽게 설..
www.whydsp.org

하지만 RBM 방법은 너무 복잡합니다.
따라서 더 간단한 방법인 Xavier 초기화 방법과, He's 초기화 방법을 이용할 수 있습니다.

위 그림은 2가지 초기화 방법을 구현한 코드 입니다.
입력 노드 갯수와, 출력 노드 갯수에 따라 초기값을 설정하는 모습을 보입니다.
이에 대한 추가적인 설명은 제가 정리한 링크에서 CP 6. 부분을 참고하셔도 됩니다.
링크: https://dryjelly.tistory.com/67
[밑바닥부터 시작하는 딥러닝] 리뷰 및 정리
딥러닝에 대한 전체적인 이해도를 높여준 책이다! 라이브러리나 프레임 워크로 구현하는 것이 아닌 책 제목처럼 '밑바닥' 부터 구현을 하기 때문에 (python 으로 구현) 추상적이던 개념들을 확실히 잡을 수 있다...
dryjelly.tistory.com
'공부 기록 > 모두를 위한 딥러닝 (Basic)' 카테고리의 다른 글
| 10-4. NN LEGO Play (0) | 2019.11.11 |
|---|---|
| 10-3. NN dropout and model ensemble (0) | 2019.11.11 |
| 10-1. ReLU: Better non-linearity (0) | 2019.11.08 |
| 9-4. Tensorboard 사용 (0) | 2019.11.08 |
| 9-3. Tensorflow를 이용한 XOR구현 (0) | 2019.11.08 |



