
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 신경망 첫걸음
- 스위치
- demultiplexing
- 운영체제
- 펌웨어
- Interrupt
- Router
- 3분 딥러닝
- 리눅스
- LED
- 딥러닝
- Transport layer
- 밑바닥부터 시작하는 딥러닝
- Generalized forward
- function call
- Switch
- 모두를 위한 딥러닝
- 모두를 위한 딥러닝]
- 신경망
- Class Activation Map
- GPIO
- RDT
- Linux
- TensorFlow
- 디바이스 드라이버
- Network layer
- 인터럽트
- LED 제어
- file descriptors
- 텐서플로우
Archives
- Today
- Total
건조젤리의 저장소
10-1. ReLU: Better non-linearity 본문
김성훈 교수님의 강의내용을 정리한 내용입니다.
출처 : http://hunkim.github.io/ml/
모두를 위한 머신러닝/딥러닝 강의
hunkim.github.io

지난 시간에는 XOR를 구현 해보았습니다.
만약 계층이 더 깊고 넓어진다면 어떤일이 일어날까요?



50%의 정확도가 나오게 되었습니다.
이유는 무엇일까요?

지난 시간에 배운 오차역전파법을 살펴보자.
y의 값이 이전 노드에서 Sigmoid노드를 거쳐서 온 값이라면 0과 1사이의 값이 될 것이고
x의 편미분값은 앞에서 전달받은 미분값에 0~1 값을 곱한값이 된다.
이 값은 뒤로 역전파 되고 0~1값이 곱해지게 될 것이다.
이러한 절차가 반복이되어 0에 가까워지게 될 것이다.

이러한 현상을 Vanishing gradient라고 한다. (제 2의 암흑기!)

이러한 문제를 해결하기 위해 Sigmoid대신 ReLU(Rectified Linear Unit)를 사용한다!
입력이 0 보다 작을 경우 0을 출력하고 그 이상일 경우 그대로 내보낸다.
출력이 0과 1사이로 제한되지 않는다!
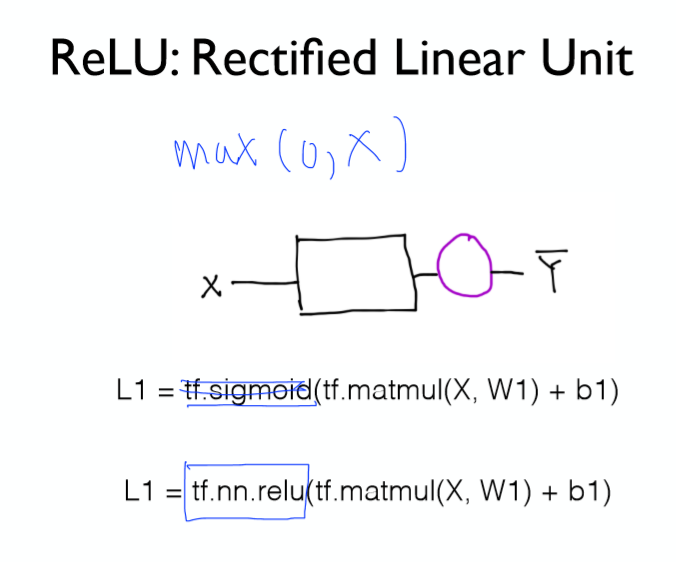


상당히 좋은 결과가 나오게 된다!

이 밖에 다양한 활성화 함수가 존재한다!
'공부 기록 > 모두를 위한 딥러닝 (Basic)' 카테고리의 다른 글
| 10-3. NN dropout and model ensemble (0) | 2019.11.11 |
|---|---|
| 10-2. Initialize weights in a smart way (1) | 2019.11.11 |
| 9-4. Tensorboard 사용 (0) | 2019.11.08 |
| 9-3. Tensorflow를 이용한 XOR구현 (0) | 2019.11.08 |
| 9-2. Backpropagation (0) | 2019.11.08 |
'공부 기록/모두를 위한 딥러닝 (Basic)' Related Articles
more




Comments