
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- Network layer
- 3분 딥러닝
- LED
- Class Activation Map
- GPIO
- TensorFlow
- 밑바닥부터 시작하는 딥러닝
- file descriptors
- Interrupt
- 리눅스
- Linux
- Generalized forward
- 펌웨어
- RDT
- 딥러닝
- function call
- LED 제어
- 텐서플로우
- 디바이스 드라이버
- Switch
- 모두를 위한 딥러닝]
- 운영체제
- 신경망 첫걸음
- demultiplexing
- 신경망
- Router
- 모두를 위한 딥러닝
- 인터럽트
- 스위치
- Transport layer
Archives
- Today
- Total
건조젤리의 저장소
4-3. Tensorflow를 이용해 File에서 Data 읽어오기 본문
김성훈 교수님의 강의내용을 정리한 내용입니다.
출처 : http://hunkim.github.io/ml/
모두를 위한 머신러닝/딥러닝 강의
hunkim.github.io

이와 같은 데이터 파일이 있다.
[x1, x2, x3, y] 구조가 줄 단위로 나열되어 있다.


만약 하나의 파일이 아닌 여러개의 파일을 읽어 학습하려면 어떻게 해야할까?
큐 구조를 이용하자!
여러개의 파일들을 큐에 넣고 관리하는 법을 알기전에 기초부터 알아보자.

- 텐서플로우는 Queue Runner를 이용하여 큐를 관리한다.
- Queue Runner는 큐에 데이터를 넣는 역할을 한다.
- Queue Runner가 큐에 어떤 데이터를 어떻게 넣을지 정의 하는 것은 Enqueue_operation이라 한다.
- Queue Runner는 멀티 쓰레드로 작동한다. 이때 쓰레드를 관리해주기 위해 별도로 Coordinator라는 것을 사용한다.
자세한 내용은 밑의 링크를 참조하자
참고 : https://bcho.tistory.com/1163
텐서플로우-파일에서 학습 데이타를 읽어보자 #1 (큐 사용 방법과 구조)
텐서플로우 - 파일에서 학습데이타를 읽어보자#1 조대협 (http://bcho.tistory.com) 텐서플로우를 학습하면서 실제 모델을 만들어보려고 하니 생각보다 데이타 처리에 대한 부분에서 많은 노하우가 필요하다는 것..
bcho.tistory.com
핵심만 정리하자면
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
import tensorflow as tf
QUEUE_LENGTH = 20
# 큐 생성 (큐의 길이, 데이터 형)
q = tf.FIFOQueue(QUEUE_LENGTH,"float")
# enqueue_operation과 QueueRunner생성
# enq_ops: 한번에 [1.0,2.0,3.0,4.0]을 큐에 넣는 operation
# QueueRunner 생성시 큐를 인자로 넘기고 list 형태로 operation 3개를 넘긴다.
# 3개를 넘겼으므로 3개의 쓰레드에 Enqeue 함수를 각각 지정한 것이다. 또한,
# qr = tf.train.QueueRunner(q,[enq_ops]*NUM_OF_THREAD) << 이런식으로 작성이 가능하다.
enq_ops = q.enqueue_many(([1.0,2.0,3.0,4.0],) )
qr = tf.train.QueueRunner(q,[enq_ops,enq_ops,enq_ops])
sess = tf.Session()
# Create a coordinator, launch the queue runner threads.
# 쓰레드 생성시 start=True로 설정하지 않을경우 쓰레드의 생성만 이루어진다.(큐에 메세지를 넣지 않음)
coord = tf.train.Coordinator()
threads = qr.create_threads(sess, coord=coord, start=True)
# 큐에서 20번 데이터를 꺼내와 출력하는 코드
for step in xrange(20):
print(sess.run(q.dequeue()))
# 쓰레드들을 모두 정지시킨다.
coord.request_stop()
# 모든 쓰레드들이 정지될때까지 대기한다.
coord.join(threads)
sess.close()
|
cs |
+ 3개의 쓰레드중 하나가 무작위로 실행되서 데이터가 출력됨
이제 파일에서 데이터를 읽는법을 알아보자.
파일 이름 출력해보기
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
import tensorflow as tf
# train.xx_input_producer(): 입력받은 큐를 만들어 준다.
# Queue Runner와 쓰레드를 생성하기 전까지는 실제로 큐에 파일명이 들어가지는 않는다.
filename_queue = tf.train.string_input_producer(["1","2","3"],shuffle=False)
with tf.Session() as sess:
coord = tf.train.Coordinator()
# 아래 함수를 이용해 QueueRunner와 쓰레드들을 한번에 생성해줌,
# 뿐만 아니라 enqueue operation까지 자동으로 생성 및 지정해줌
threads = tf.train.start_queue_runners(coord=coord,sess=sess)
# 실행시 1,2,3 이 순차적으로 반복되서 나옴
# 랜덤하게 섞기 위해서는 shuffle=True로
for step in xrange(10):
print(sess.run(filename_queue.dequeue()) )
coord.request_stop()
coord.join(threads)
|
cs |
파일에서 데이터 읽어오기
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
import tensorflow as tf
from numpy.random.mtrand import shuffle
#define filename queue
filename_queue = tf.train.string_input_producer(['/Users/terrycho/training_datav2/queue_test_data/b1.csv'
,'/Users/terrycho/training_datav2/queue_test_data/c2.csv']
,shuffle=False,name='filename_queue')
# define reader
# TextLineReader를 이용해 파일을 읽게되면 한줄씩 순차적으로 읽어온다.
reader = tf.TextLineReader()
key,value = reader.read(filename_queue)
#define decoder
record_defaults = [ ["null"],[1],[1900],["null"],["null"]]
id, num, year, rtype , rtime = tf.decode_csv(
value, record_defaults=record_defaults,field_delim=',')
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(100):
print(sess.run([id, num, year, rtype , rtime]))
coord.request_stop()
coord.join(threads)
|
cs |
본론으로 돌아와서...
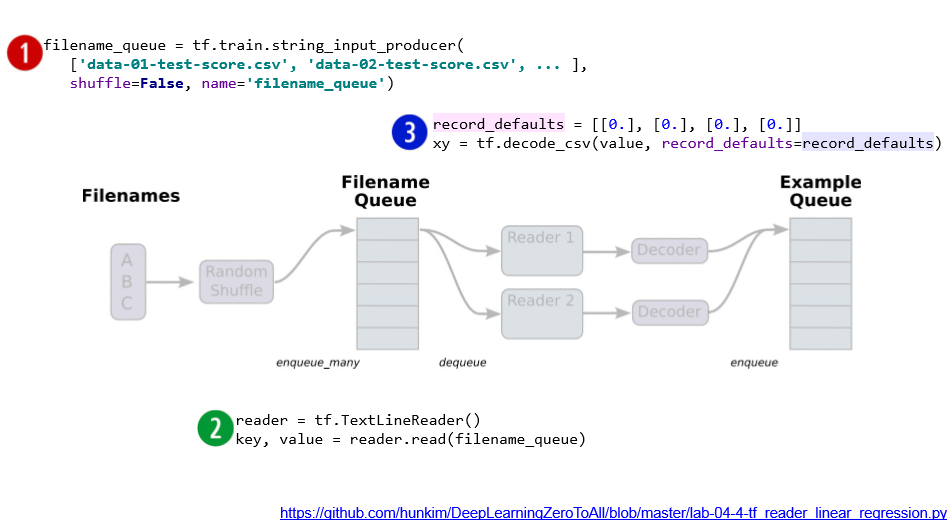

* tf.train.batch: 데이터를 한번에 묶어서 보내주는 함수, Session으로 실행시켜 주어야 한다.
'공부 기록 > 모두를 위한 딥러닝 (Basic)' 카테고리의 다른 글
| 5-2. Tensorflow를 이용한 Logistic (regression) classifier구현 (0) | 2019.11.07 |
|---|---|
| 5-1. Logistic (regression) classification (0) | 2019.11.07 |
| 4-2. Tensorflow를 이용한 Multi-variable linear regression구현 (0) | 2019.11.06 |
| 4-1. Multi-variable linear regression (0) | 2019.11.06 |
| 3-2. Tensorflow를 이용한 Minimizing Cost확인 (0) | 2019.11.06 |
'공부 기록/모두를 위한 딥러닝 (Basic)' Related Articles
more




Comments