
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 텐서플로우
- LED
- demultiplexing
- 인터럽트
- 딥러닝
- LED 제어
- Network layer
- 신경망 첫걸음
- 리눅스
- GPIO
- 디바이스 드라이버
- 밑바닥부터 시작하는 딥러닝
- Transport layer
- Interrupt
- Generalized forward
- 신경망
- 모두를 위한 딥러닝
- TensorFlow
- 운영체제
- Switch
- Class Activation Map
- RDT
- function call
- file descriptors
- 3분 딥러닝
- Linux
- 모두를 위한 딥러닝]
- Router
- 스위치
- 펌웨어
- Today
- Total
건조젤리의 저장소
CNN의 관심영역을 확인해보자 (CAM) 본문

CNN을 해석하기 위해서는 어떻게 해야할까?
기본적인 CNN구조에서는 Convolution Layer를 이용하여 특징을 뽑아낸 후 Fully-Connected Layer(FC)를 통과시켜 class의 분류를 수행한다. FC를 통과시키기 위해 Convolution을 이용해 뽑은 특징점의 Flatten과정을 거치게 되고 위치 정보들이 소실된다.
만약 이러한 위치 정보들이 소실되지 않고 유지되며 class분류를 수행할 수 있다면, CNN이 각 class를 분류하는데 중요한 위치정보를 알 수 있지 않을까?
Learning Deep Features for Discriminative Localization 논문에서는 특징점의 Flatten과정 대신 각 채널별로 Global Average Pooling(GAP)을 적용하는 방법을 이용하여 class의 분류를 수행한다.
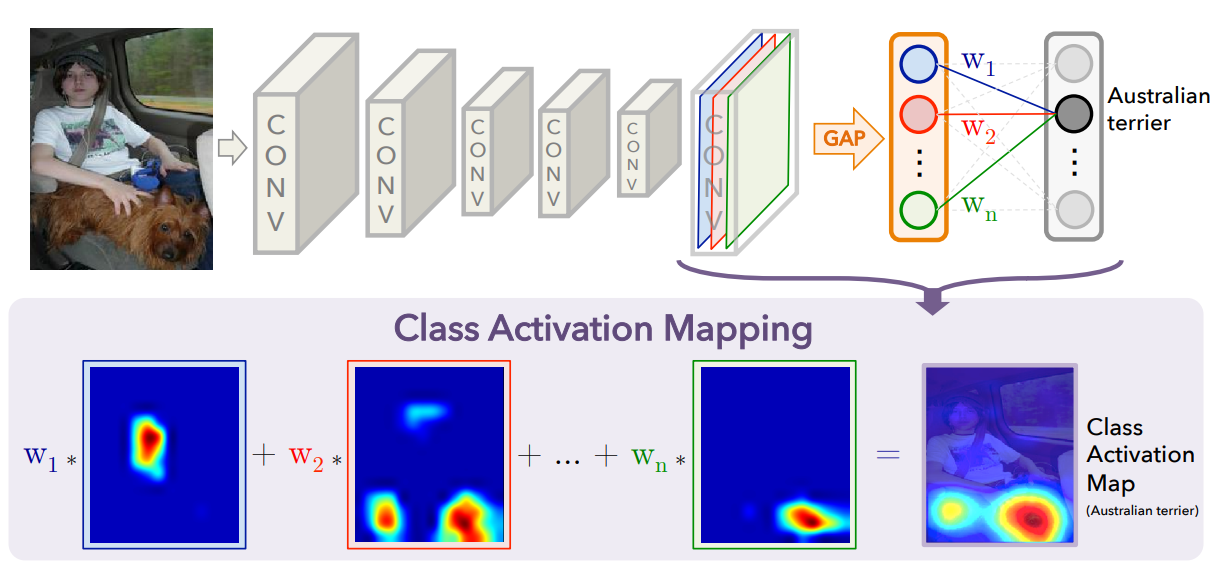
$n$번째 채널의 정보가 Australian terrier라는 클래스에 얼마나 영향을 미치는지 $w_{n}$가중치로 나타나게 되고, 이를 각 채널들과 곱하여 더해주게 되면 $n$번째 클래스에 영향을 미치는 위치 정보(Class Activation Map : CAM)를 알 수 있다!
예를 들어 설명하자면 다음과 같다.
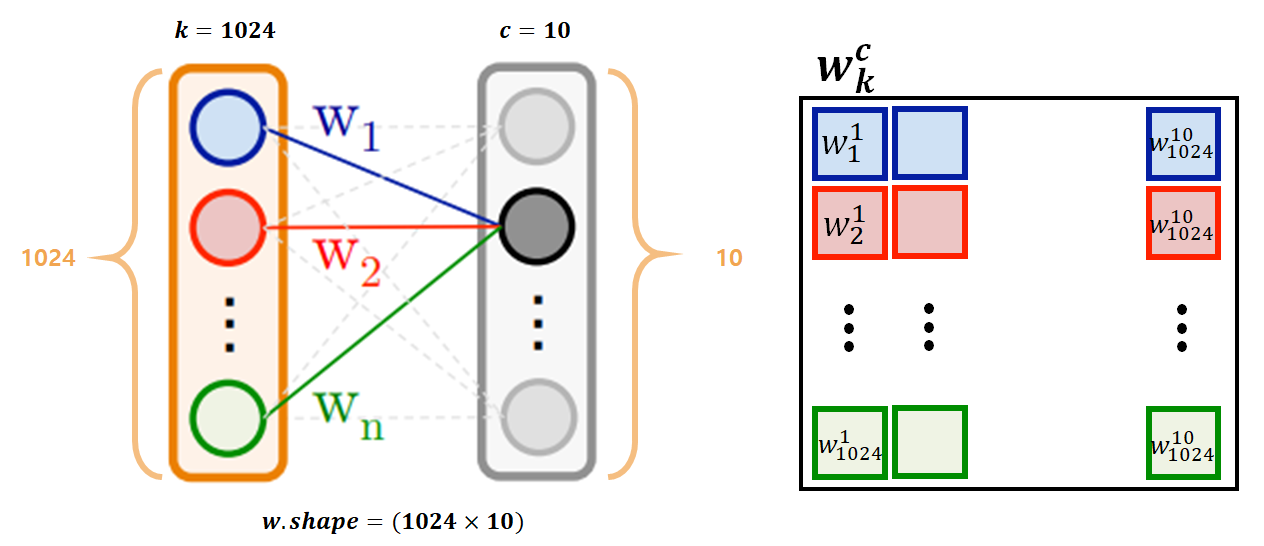
만약 1024개의 채널 $k=1024$, 10개의 class $c=10$가 있다면 가중치 $w_{k}^{c}$는 위 그림과 같은 형식이 될 것이다.
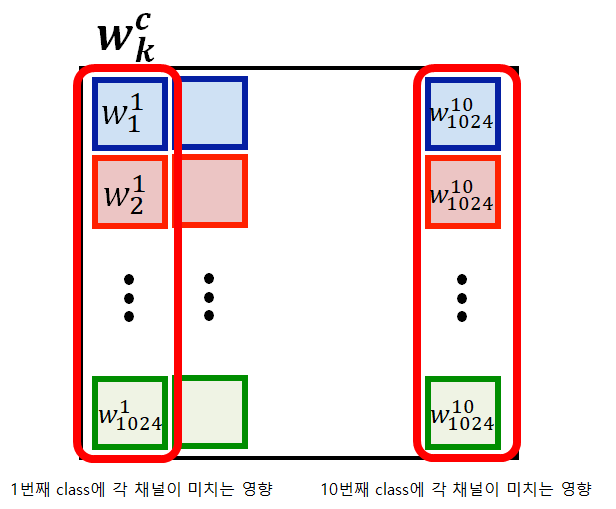
$w_{k}^{c}$의 구조를 자세히 보면 위 그림과 같다.
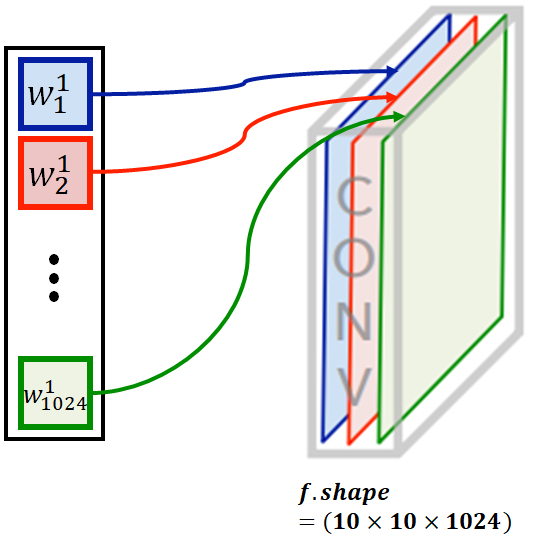
먄약 1번째 class에 각 채널이 미치는 영향을 시각화 하고 싶다면 각각의 영향값을 해당하는 채널에 곱하여 더하면 된다.
이를 수식으로 나타내면 다음과 같다.
$k$번째 채널의 값들 중 $(x,y)$에 위치한 값
$$f_{k}(x,y)$$
GAP을 거친 값
$$F^{k} = \sum_{x,y}f_{k}(x,y)$$
class $c$에 대해 softmax입력으로 주어지는 값
$$S_{c} = \sum_{k}w_{k}^{c}f_{k}$$
여기서 $w_{k}^{c}$ 가 $k$번째 채널과 class $c$에 대응하는 값이라면 $w_{k}^{c}$ 는 class $c$에서 $F^{k}$의 중요성을 나타낸다.
$S_{c}$ 에서 $F^{k}$를 풀어서 정리하면
$$S_{c} = \sum_{x,y}\sum_{k}w_{k}^{c}f_{k}(x,y)$$
$M_{c}$는 $c$에 대한 CAM
$$M_{c}(x,y) = \sum_{k}w_{k}^{c}f_{k}(x,y)$$
따라서 $S_{c}$는
$$S_{c} = \sum_{x,y}M_{c}(x,y)$$
즉, $M_{c}$는 $(x,y)$에 위치한 값이 $c$ class로 분류되는데 미치는 중요도를 나타낸다!
위 수식에 대한 더욱 자세한 설명은 이 블로그에 자세히 설명되어 있으니 확인바랍니다.
이제 케라스를 이용하여 5가지의 꽃 데이터들을 사용하여 어떤 꽃인지 분류하고, CNN의 관심영역을 추출해 봅시다.
코드 (환경 : 텐서플로, 케라스)
- 모듈 임포트
%matplotlib inline
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import cv2
import pathlib
import random
from PIL import Image
- 데이터 준비 및 데이터 파이프라인 설정
data_dir = tf.keras.utils.get_file(origin='https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
fname='flower_photos', untar=True)
data_dir = pathlib.Path('/home/esdl/.keras/datasets/flower_photos')
label_names={'daisy': 0, 'dandelion': 1, 'roses': 2, 'sunflowers': 3, 'tulips': 4}
label_key=['daisy','dandelion','roses','sunflowers','tulips']
all_images = list(data_dir.glob('*/*'))
all_images = [str(path) for path in all_images]
random.shuffle(all_images)
all_labels=[label_names[pathlib.Path(path).parent.name] for path in all_images]
data_size=len(all_images)
train_test_split=(int)(data_size*0.2)
x_train=all_images[train_test_split:]
x_test=all_images[:train_test_split]
y_train=all_labels[train_test_split:]
y_test=all_labels[:train_test_split]
IMG_SIZE=160
BATCH_SIZE = 32
def _parse_data(x,y):
image = tf.read_file(x)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.cast(image, tf.float32)
#image = (image/127.5) - 1 # -1 ~ 1
image = (image/255.0) # 0 ~ 1
image = tf.image.resize_images(image, (IMG_SIZE, IMG_SIZE))
return image,y
def _input_fn(x,y):
ds=tf.data.Dataset.from_tensor_slices((x,y))
ds=ds.map(_parse_data)
ds=ds.shuffle(buffer_size=data_size)
ds = ds.repeat()
ds = ds.batch(BATCH_SIZE)
ds = ds.prefetch(buffer_size=1)
return ds
train_ds=_input_fn(x_train,y_train)
validation_ds=_input_fn(x_test,y_test)
- VGG-16 model 불러오기
vgg_model = tf.keras.applications.VGG16(weights = 'imagenet',
include_top = False,
input_shape=(IMG_SIZE, IMG_SIZE, 3))
vgg_model.summary()저는 imagenet으로 학습된 vgg_16 모델을 사용하겠습니다.
- vgg_16 모델에 1024개의 채널을 갖는 Conv레이어와 GAP, FC를 추가합니다.
model = tf.keras.Sequential()
for layer in vgg_model.layers[:-1]: # just exclude last layer from copying
model.add(layer)
for layer in model.layers:
layer.trainable = False
model.add(tf.keras.layers.Conv2D(filters=1024, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(tf.keras.layers.GlobalAveragePooling2D())
model.add(tf.keras.layers.Dense(len(label_names), activation='softmax'))
- 모델을 컴파일 하고 학습을 시작합니다.
model.compile(optimizer=tf.train.AdamOptimizer(),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=["accuracy"])
history = model.fit(train_ds,
epochs=100,
steps_per_epoch=2,
validation_steps=2,
validation_data=validation_ds)
- 정확도와 loss를 확인합니다. 정확도 80%이상을 달성하면 성공입니다.
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()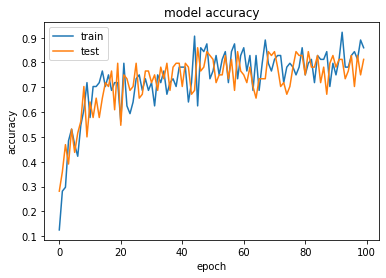
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()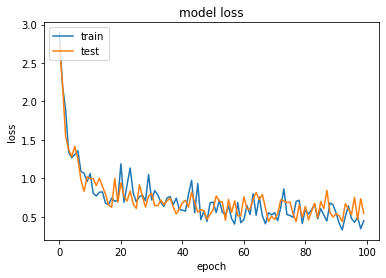
- 이제 CNN의 관심영역이 어디인지 계산해 봅시다.
get_output = tf.keras.backend.function([model.layers[0].input],
[model.layers[-3].output, model.layers[-1].output])
[conv_outputs, predictions] = get_output([데이터를 입력!])
class_weights = model.layers[-1].get_weights()[0]관심영역을 계산하기 위해서 $M_{c}$를 계산해야 합니다. 수식을 다시한번 보겠습니다.
$$M_{c}(x,y) = \sum_{k}w_{k}^{c}f_{k}(x,y)$$
$f_{k}(x,y)$ 값은 마지막 conv계층의 출력값 입니다. (conv_output)
$w_{k}^{c}$ 값은 모델의 마지막 계층의 가중치값 입니다. (class_weights)
- 모델이 출력한 예측값을 토대로 CAM($M_{c}$)을 계산합니다.
output = []
for num, idx in enumerate(np.argmax(predictions,axis=1)):
cam = tf.matmul(np.expand_dims(class_weights[:,idx],axis = 0),
np.transpose(np.reshape(conv_outputs[num],(10*10,1024))))
cam = tf.keras.backend.eval(cam)
output.append(cam)
계산된 cam값들을 원본 이미지에 맞게 resize후, colorMap처리를 하여 heatmap을 얻습니다.
그 다음 원본 이미지와 겹쳐서 출력해 보았습니다.

CNN의 관심 영역을 확인할 수 있다!
[전체 코드]
https://github.com/Dryjelly/CAM_class-activation-mapping
[참고한 github 및 자료]
https://arxiv.org/abs/1512.04150 [paper]
https://kangbk0120.github.io/articles/2018-02/cam [CAM의 전체적인 설명]
https://jsideas.net/class_activation_map/ [CAM을 이용한 얼굴 위치 추적]
https://github.com/KangBK0120/CAM [CAM github code]
https://androidkt.com/how-to-use-vgg-model-in-tensorflow-keras/ [VGG model in Keras]
'공부 기록 > 인공지능' 카테고리의 다른 글
| Tensorflow 에서 데이터 Batch처리 손쉽게 구현하기 (0) | 2020.01.06 |
|---|---|
| MNIST 예제의 정확도가 너무 낮게 나온다면? (정규화의 중요성) (0) | 2020.01.06 |
| [ML] 코세라 머신러닝 강의 팁 (0) | 2020.01.06 |
| [ML] Backpropagation의 이해 (0) | 2020.01.06 |
| [ML] Normal Equation의 증명 (0) | 2020.01.06 |



